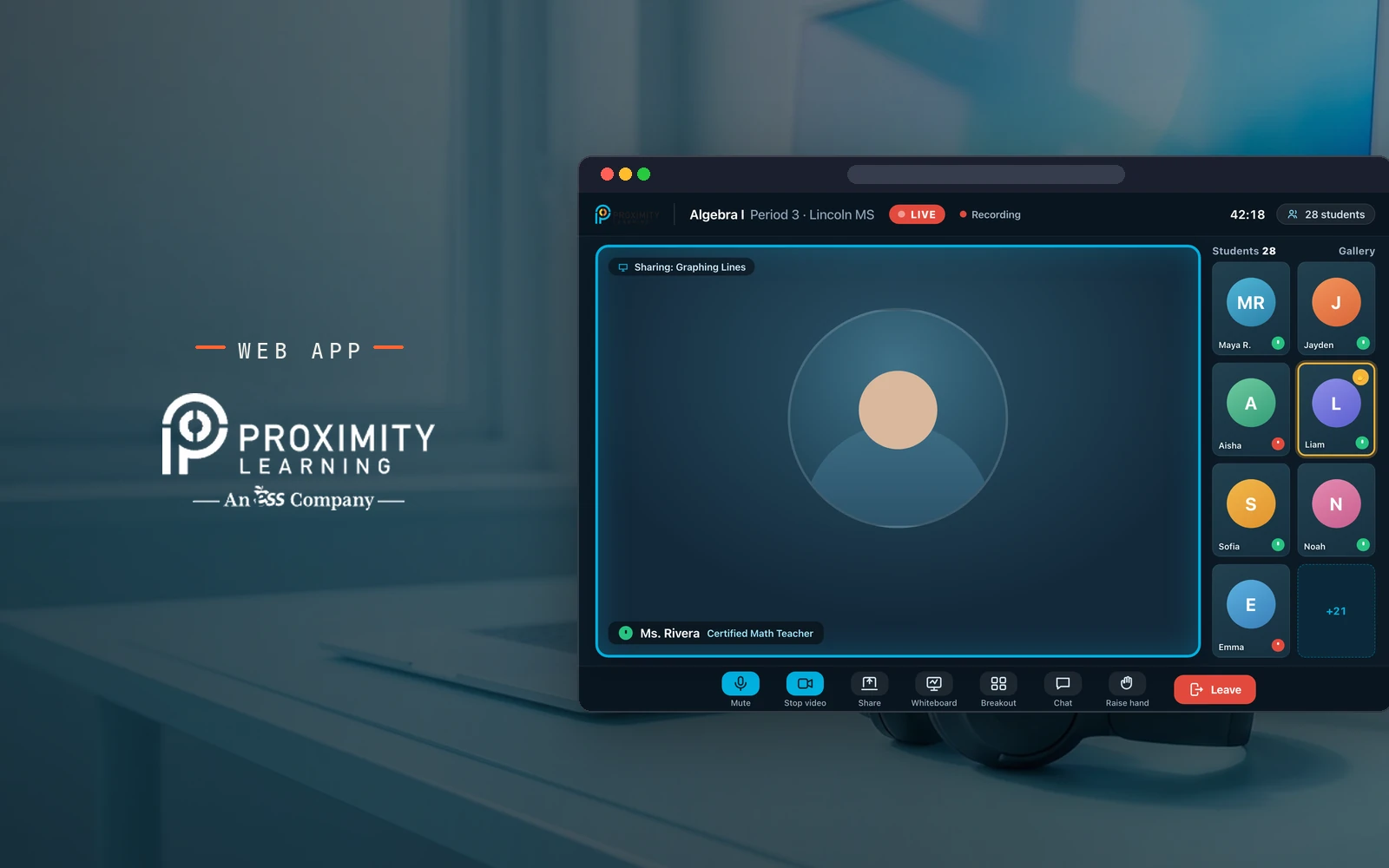
01 · Tool use
Tool-using agents
Agents that call your APIs, query your data and trigger real workflows, with every action scoped, approved where it matters and logged.
LangGraph · function calling · MCP · OpenTelemetry
Primary research for the answer-engine era, our most-cited piece.
Five constraint numbers locked before build. Six stages from discovery to hand-off.

Resourcifi is an AI agent development company. We build production AI agents that plan, call your systems and take action under guardrails and human checkpoints, scoped to exactly what they may do, measured against an eval suite and shipped to five deployment numbers. Tool use, multi-agent coordination, agentic RAG and the observability to run it live.
AI agent development, the core of agentic AI development, is building software that can plan and take actions across your systems, calling APIs, querying data and triggering workflows, not only generating text. A production AI agent, sometimes called an autonomous AI agent, is scoped to exactly what it may do, measured by an eval suite, and observable while it runs.
The category is moving from pilots to production fast. MarketsandMarkets values the AI agents market at USD 7.84 billion in 2025 and projects USD 52.62 billion by 2030, a 46.3% CAGR. The opportunity is real, and so is the bar to ship one that holds up.
The demo is the easy part. What decides whether an agent ships is the guardrails, the cost per run, the task-success floor and the recovery path when a step fails. That is the gap most agent projects never cross, and the part we engineer first.
Related: AI application development, RAG development and AI workflow automation.
An agent that can act is only safe if you can measure it. So we fix the numbers that decide go-live before a line of code, on every engagement.
Hit the numbers, it ships. Miss one, it does not go live.
See how we enforce them →An agent that looks great in a scripted demo meets real users, real data and real edge cases, and the failure modes show up: a tool call that errors, a plan that loops, a cost that triples, an action no one approved. Gartner predicts over 40% of agentic AI projects will be canceled by the end of 2027, citing escalating costs, unclear business value and inadequate risk controls. In our experience the projects that stall are rarely short on model quality. They are short on the engineering around the model.
So we build that engineering first: scoped permissions, an eval set, cost and latency budgets, and a recovery path, then the agent itself.
How we close the gap →Agents that call your APIs, query your data and trigger real workflows, with every action scoped, approved where it matters and logged.
Planner and worker agents that divide a task and coordinate through shared state, added only when a single agent genuinely cannot do the job.
Retrieval an agent can reason over and re-query, measured for citation accuracy, not a one-shot lookup. Hybrid search and reranking where it earns its keep.
Scoped permissions, approval gates for high-impact actions, a policy layer that blocks anything out of scope, and a full audit log, so an agent can take action while staying inside its scope.
Reference, adversarial and regression evals run in CI, plus tracing in production, so the agent's accuracy and cost are measured, not asserted.
Canary rollout, cost dashboards, on-call and a model-upgrade path, so the agent survives real traffic and a real budget, with a rollback if a number is missed.
An agent is a loop, not a single answer. It plans a step, takes one action through a tool, observes the result, then decides the next step, until the goal is met or it hands back to a human. Guardrails wrap every action; evals watch the whole run.
Not a chatbot reply. A real run: the agent reads the goal, plans, calls the tools it is allowed to use, checks its work, and stops to ask before anything irreversible. This is an illustration of an agent reconciling failed payments under guardrails.
See agentic automation →Illustration: an AI agent reconciles yesterday's failed payments, retries temporary declines, drafts card-update emails for human approval, and flags suspected fraud without acting.
Across live products we have shipped RAG assistants, copilots and action-taking agents to strict latency, cost and task-success targets. About a third of our agent work is finishing a build another team could not get past a demo.
Support, onboarding and in-app copilots that resolve a request end to end, escalate cleanly, and stay inside scoped permissions.
Reconciliation, triage, data entry and multi-step back-office workflows, with approval gates on anything that touches money or records.
Agentic RAG over your knowledge base and systems, citation-checked, so answers are grounded and traceable, not guessed.
The same operating discipline runs every agent we build: the five numbers locked before we start, an eval suite that has to pass, guardrails wrapped around every action, and a hand-off engineered from day one.
Read the full method →We pressure-test the use case and whether an agent is even the right tool, then agree the five numbers.
Your named engineering lead examines your data, systems and the tools the agent must use, and writes the eval set.
The five numbers, the guardrails and the scope are locked before the build begins.
Tools, planning and guardrails engineered against the eval suite from day one, with cost and accuracy tracked in CI.
Canary rollout from 1% to 100%, watched against the numbers, with a rollback path and a human approval gate.
Dashboards, tracing, a model-upgrade path and a paired hand-off so your team owns it.
Our AI agent development services run from a fixed-scope assessment to a dedicated team. Whether you need us to build AI agents end to end or embed engineers in yours, start here.
A fixed-scope engagement: feasibility, the five numbers, an eval set and a build plan you can take anywhere.
A scoped agent built to the numbers and shipped in a staged rollout, with guardrails and observability from day one.
An embedded pod that builds, runs and improves your agents alongside your team, on a monthly engagement.
Indicative cost ranges are in the FAQ below. Or hire AI agent developers for your own roadmap.
We were thoroughly happy and impressed with the constant communication.
Sam Ziaripour Founder and CEO, Blindspots
It was as if we had people in-house working with us.
Rick Stahl CEO, H-BAR C Ranchwear
They were excellent to work with and stayed in constant communication.
Christopher Dietrich Founder and CEO, HART
I would recommend them to anybody with any kind of tech needs.
Mitchell Clauser Marketing, Revenue Media Group
The product was exactly what we were hoping for.
Chris Cote President, Scentco
They have been amazing for the past six months.
Rick Buffington CEO, Shoprocket
Their communication has been just outstanding.
Jesse Lo Re Founder and CEO, e-coalition
Answered the way we would on a scoping call, not the way a brochure would.
A chatbot generates replies. An agent plans and takes actions: it calls APIs, queries data and triggers workflows to get something done, then reports back. That power is also the risk, which is why we build guardrails, scoped permissions and human checkpoints before we ship.
We start from the goal and the data, define the tools the agent may call, then build the loop: plan, act through a tool, observe, repeat, under scoped permissions. We build agents from scratch in Python on LangGraph or CrewAI with FastAPI and vLLM, or extend an existing codebase. We write an eval set before the build, track cost and task-success in CI, and add multi-agent coordination only if one agent cannot do the job. It ships through a staged rollout with a rollback path.
Scoped permissions for every tool the agent can touch, approval gates for high-impact actions, a policy layer that blocks anything out of scope, and a full audit log. Each action is observable, and there is always a safe fallback and a rollback path.
Our median time to a first production AI deployment is about 90 days. A scoped single-agent workflow can be faster; a multi-agent system with deep integrations takes longer. The timeline depends on data readiness, the tools the agent must use and your risk review.
A fixed-scope agent assessment runs roughly $20-40k over 2-3 weeks. A milestone build runs roughly $90-180k over 8-14 weeks with a small pod. A dedicated agent team runs $50-150k per month. Cost per run is one of the five numbers we agree up front, and our global delivery model gives you senior talent at a fraction of comparable onshore cost.
Yes, with planner and worker agents that coordinate through shared state and a message queue. We add the coordination only when one agent genuinely cannot do the job, because every extra agent adds cost and failure modes to manage.
We map the tool to the job rather than to a trend. Orchestration with LangGraph or CrewAI, retrieval with pgvector and rerankers, evals with an eval harness and LangSmith, tracing with OpenTelemetry, serving with vLLM and FastAPI. Most of our agent work is in Python. We use frontier models from OpenAI, Anthropic and Google, plus open-weight Llama or Mistral when on-prem or cost rules it.
An eval suite written before the build: reference cases, adversarial cases and regression tests, run in CI on every change. Combined with tracing in production, the agent's accuracy and cost are numbers you can watch on every change.
Ask how they measure success before they build, what guardrails wrap each action, and what happens when a step fails. A serious AI agent development company will name the numbers it commits to, show you an eval set, and put a senior engineer on the call. If the answer is a demo with no plan for production, that is the gap most projects fall into.
Yes. About a third of our AI engagements start there. We assess what exists, set the five numbers that were never defined, and rebuild only what blocks production, then give you a fixed scope to live.









Every agent engagement is scoped by a senior engineer you meet before contracts are signed. See how we deliver in Production-First AI™.
A senior engineer on the call, not a sales pitch. Thirty minutes, your actual use case, a straight answer on whether an agent is the right tool.
Reviewed by Kanika Mathur, Head of Service Delivery, Resourcifi Inc.
We use cookies to analyze traffic and improve your experience. See our Privacy Policy.