What does a dedicated data scientist actually do day to day?
A data scientist frames a business problem in terms of data, then runs the analysis and experiments that prove whether a solution is worth building before anyone commits engineering headcount. Day to day that means pulling and cleaning data, exploring it for signal, building and validating models or statistical tests, and translating the result into a decision a stakeholder can act on. Most of the work happens in notebooks and SQL, and the real output is a defensible answer plus the evidence behind it, not a deployed service. At Resourcifi this sits upstream of build work, so a data scientist confirms the lift is real before our ML engineers productionize anything.
What is the difference between a data scientist, an ML engineer and an AI engineer?
A data scientist frames the problem, runs experiments and proves there is measurable lift, working mostly in notebooks and statistics. An ML engineer takes a validated model and makes it a reliable production system with feature pipelines, training, serving and monitoring, usually for custom models you own. An AI engineer works one layer up, composing foundation models, agents and retrieval into product features and owning the evals that keep generative output trustworthy. The lanes overlap, so the buying decision usually comes down to whether you are validating an idea, productionizing a custom model, or shipping a feature on top of existing models. You can compare all three at https://www.resourcifi.com/hire/.
What skills and stack should I expect from a senior data scientist?
Expect strong applied statistics and experimental design, fluency in Python with pandas, NumPy, scikit-learn and a notebook environment, and confident SQL for getting at the data directly. Most seniors also work with a modeling stack such as statsmodels, XGBoost or PyTorch, visualization tools, and a cloud data warehouse like Snowflake, BigQuery or Databricks. The skill that separates senior from mid-level is judgment: knowing which question is worth answering, which method actually fits, and how to communicate uncertainty so a business leader can decide. Resourcifi matches the specific stack to your environment rather than imposing one.
What engagement and pricing models do you offer for hiring data scientists?
We mainly staff dedicated data scientists who work as a full-time extension of your team, plus project-based or fractional arrangements when the scope is narrower, such as a single experiment or feasibility study. You manage priorities directly and we handle hiring, retention and replacement. On cost, our rates are typically about 70% below comparable onshore rates for equivalent seniority. We scope the structure to your timeline and budget rather than forcing one model on you.
How do you vet data scientists and make sure they are genuinely senior?
Every data scientist you hire is scoped and named by a senior engineer you meet and interview before any contract is signed, so you judge the actual person rather than a CV. We match from our 200+ in-house experts, screening for applied statistical depth, real experimentation experience and the ability to explain a result to a non-technical stakeholder. We have been doing this since 2017, hold a 4.9 rating on Clutch and see 95% repeat clients, which is hard to sustain if the people are not strong. If a match is not working, we replace them rather than leaving you to manage the problem.
How quickly can a data scientist start on our project?
Because we match from 200+ in-house experts rather than recruiting cold, a working data scientist typically starts fast once we have agreed the scope and you have interviewed the candidate. The gating step is usually your access setup, data access, warehouse credentials and a clear first question, rather than finding the person. We deliberately keep you in the loop on the match so onboarding is a handoff to someone you already chose, not a surprise. From there a senior data scientist can be productive on exploratory work within the first week.
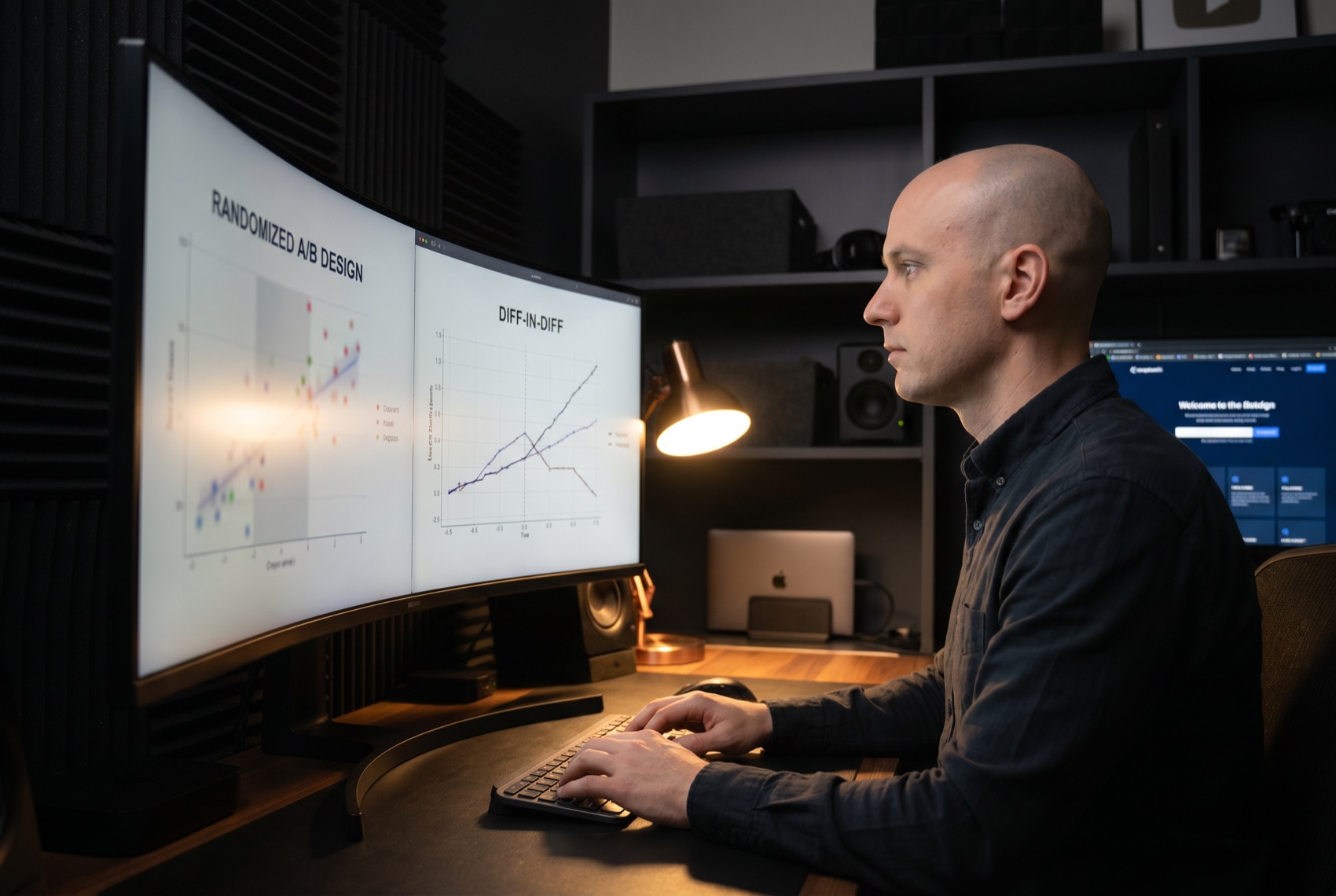
How rigorous is your approach to A/B testing?
We treat A/B testing as a discipline, not a dashboard toggle. That means deciding the primary metric and minimum detectable effect up front, running a power calculation to size the test before it launches, checking randomization and sample ratio, and holding the test for its planned duration instead of peeking and stopping early. We are explicit about multiple-comparison risk when several variants or metrics are in play, and we report confidence intervals rather than a bare win or lose. The goal is a result you can defend to a skeptical stakeholder, which is exactly the standard our Production-First AI (TM) method expects upstream of any build at https://www.resourcifi.com/our-method/.
Can your data scientists do causal inference, not just correlation?
Yes. When a clean randomized experiment is not possible, our data scientists use causal methods to estimate real effect rather than reporting correlation and hoping. Depending on the data that can mean difference-in-differences, regression discontinuity, instrumental variables, propensity-score matching or synthetic control, with the assumptions behind each one stated plainly. The harder part is judgment about which design the data can actually support, and a senior data scientist is honest about when the answer is only directional. This matters most for decisions like measuring the impact of a change you cannot ethically or practically randomize.
How do you decide whether an AI or ML idea is feasible before we invest?
We run a go or no-go feasibility study before committing build headcount, which is the core reason to bring in a data scientist early. That means checking whether you have enough data of sufficient quality, establishing a baseline to beat, estimating the achievable lift, and pressure-testing whether the predicted value justifies the cost of building and maintaining the system. A good study ends in a clear recommendation: build it, reshape the problem, or do not build it yet and here is why. This keeps spend honest and is the same discipline behind our Production-First AI (TM) approach, where nothing graduates to engineering until the evidence supports it.
Can you audit an experimentation program that we no longer trust?
Yes, this is common work. We start by auditing how tests are designed, sized and called: whether metrics are defined up front, whether randomization is sound, whether results are being stopped early on a peek, and whether multiple comparisons are inflating false positives. From there we rebuild the parts that are broken, standardize a test template, and put guardrails in place so future results are credible by default. The usual outcome is fewer tests run but far more of them trusted, because the cheapest experiment is the one you do not have to re-run after losing faith in it.
How do the data science, ML and AI lanes fit together on a real project?
They run in sequence and then in a loop. A data scientist goes first to frame the problem, prove there is lift and produce a model worth shipping; an ML engineer then turns that into a reliable production system with pipelines, serving and monitoring; an AI engineer handles any layer built on top of foundation models, agents or retrieval. Once it is live the data scientist comes back to measure real-world impact and feed the next iteration. Many real systems need all three at different stages, which is why we let you mix lanes from one bench rather than forcing a single title. You can see how the lanes line up at https://www.resourcifi.com/hire/.
How much does it cost to hire a data scientist in the US?
A full-time senior data scientist in the United States is expensive. The U.S. Bureau of Labor Statistics put the 2024 median wage at 112,590 dollars, and fully loaded cost with benefits, recruiting and overhead typically lands well above that. Hiring through Resourcifi changes the math: you engage a named, vetted senior on a per-scientist-per-month basis, typically about 70% below comparable onshore rates for equivalent seniority, with no recruiting fee and no long-term liability. You can scale from a single dedicated scientist to a small analytics pod, and step down again, without the cost of building and unwinding an in-house team.
Should I hire an in-house data scientist or outsource to an agency?
It depends on how steady and central the work is. A permanent in-house hire makes sense when data science is core to the product and you have a continuous backlog to justify a full-time salary and a months-long search. Outsourcing to an agency fits better when you need senior judgment quickly, the workload is project-shaped, or you want to validate the value before committing headcount. Resourcifi gives you the middle path: a dedicated data scientist who works as an extension of your team, named and interviewed before you sign, matched from our 200+ in-house experts, on a global delivery model that is typically about 70% below comparable onshore rates. If the fit is wrong we replace the scientist rather than leaving you to manage it.