What does a dedicated ML engineer actually do day to day?
A dedicated ML engineer spends most of the day on the path between a model and production: cleaning and pipelining data, training and tuning models, then wrapping them in services with monitoring and tests. Less time goes to inventing novel algorithms than people expect. They also debug data quality issues, watch live metrics, and retrain when performance slips. The job is closer to engineering with statistics than to pure research.
What is the difference between an ML engineer, an AI engineer and a data scientist?
A data scientist focuses on analysis, experimentation and explaining what the data says, often in notebooks. An ML engineer turns models into reliable production systems with pipelines, serving and monitoring. An AI engineer typically builds on top of existing foundation models and APIs, doing prompt design, retrieval and orchestration rather than training models from scratch. The lines blur, so define the outcome you need before you pick a title.
What skills and stack should I expect from a strong ML engineer?
Expect solid Python plus PyTorch or TensorFlow, comfort with data tooling like pandas, Spark or SQL, and real software engineering habits such as version control, testing and clean APIs. On the operations side, look for Docker, a cloud platform, and MLOps tooling for experiment tracking and deployment. The strongest engineers also understand the math well enough to know why a model is failing, not just that it is.
What engagement and pricing models do you offer for dedicated ML engineers?
We mainly staff dedicated engineers who work as a full-time extension of your team, plus project-based or fractional arrangements when the scope is narrower. You manage priorities directly and we handle hiring, retention and replacement. On cost, our rates are typically about 70% below comparable onshore rates. We scope the model to your timeline and budget rather than forcing one structure.
How do you vet ML engineers and confirm real seniority?
Every engineer goes through technical screening, hands-on assessment of ML and engineering skills, and a review of past production work, not just credentials. We probe for people who have shipped models to real users and handled the messy parts like data drift and retraining. Resourcifi holds a 4.9 rating on Clutch, which reflects how the vetting holds up in practice. You also interview candidates yourself before committing.
How quickly can a dedicated ML engineer onboard and start contributing?
Because we have 200+ experts already employed in-house, we can usually match and place a qualified ML engineer in days rather than running a months-long search. Real contribution depends on your codebase and data access, but a senior engineer typically ramps within the first week or two. We front-load environment access, documentation review and a clear first task so the engineer is productive early instead of waiting.
Can your ML engineers work inside our existing stack and tooling?
Yes. Our engineers adapt to your repositories, cloud accounts, CI pipelines and data platforms rather than imposing their own. Whether you run on AWS, GCP or Azure, and whatever your serving and experiment-tracking tools are, we match the people to your environment. This is part of our Production-First AI™ approach, where the goal is a model that runs reliably in your systems, not a demo in isolation.
How do your engineers handle model drift and retraining over time?
Good ML work does not stop at deployment, because real-world data shifts and models quietly degrade. Our engineers set up monitoring on input distributions and prediction quality so drift is caught before it hurts users. They build retraining pipelines, often automated on a schedule or triggered by metric thresholds, with validation gates so a worse model never ships. The aim is a system that stays accurate without a fire drill every quarter.
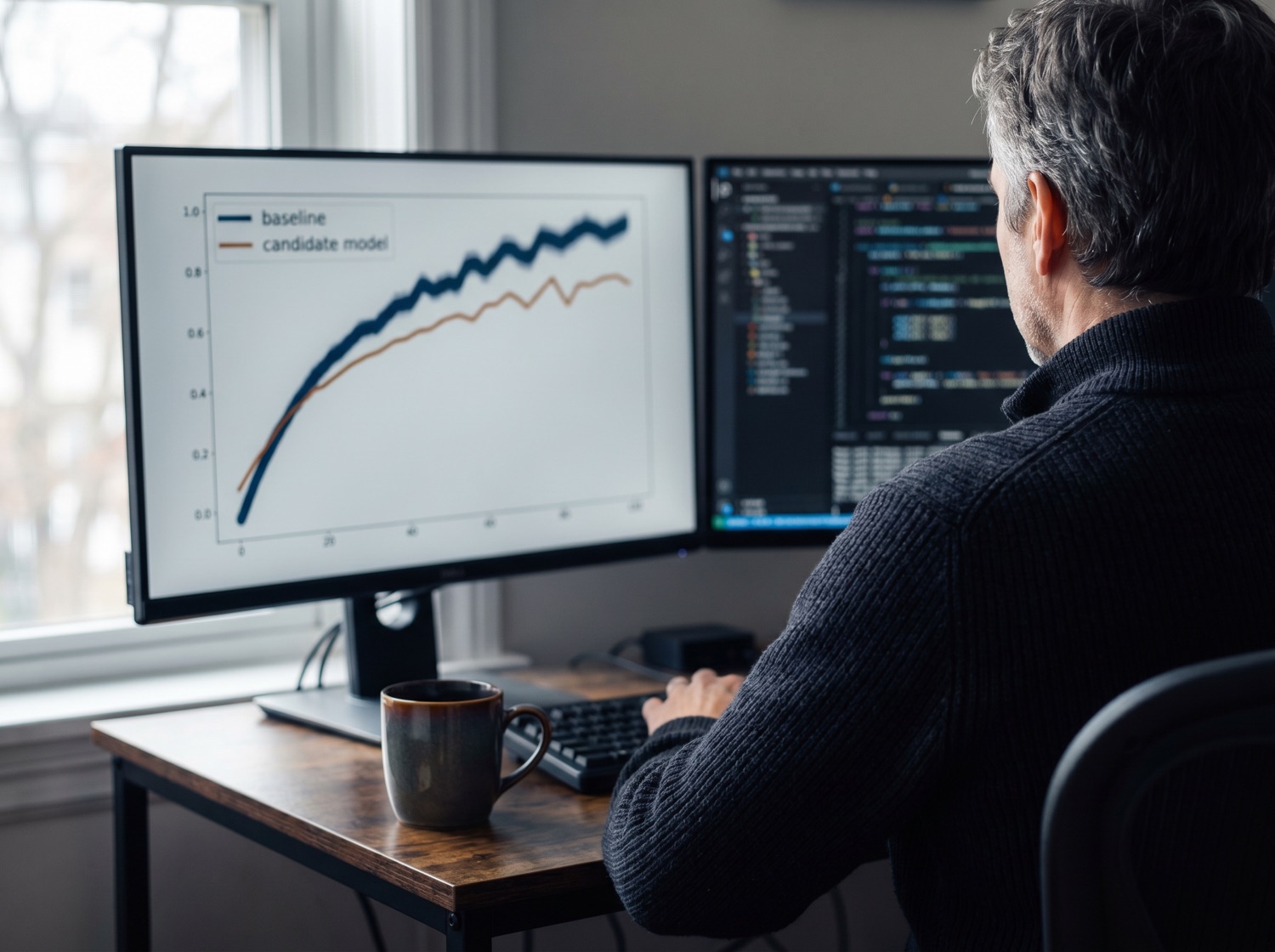
Why do you emphasize baseline discipline before building complex models?
A simple baseline, like a logistic regression or even a sensible heuristic, tells you whether a problem is worth a heavy model at all. Without it, teams burn weeks tuning deep networks that barely beat a one-line rule. Our engineers establish a baseline first, then justify every added layer of complexity against it. This keeps projects honest, faster to ship, and far easier to debug when something goes wrong.
Can you take over a stalled or half-finished ML model?
Yes, and it is common work. We start by auditing what exists: the data, the training code, the evaluation setup, and whether the original metrics were even measuring the right thing. Often the model stalled because of leaky data, a missing baseline, or no path to production rather than the algorithm itself. We stabilize the foundation first, then move it toward a deployable, monitored system.
How do ML engineer, AI engineer and data scientist hiring lanes fit together?
Think of them as a pipeline rather than rivals. Data scientists frame the problem and prove what is possible, ML engineers make it production-grade and durable, and AI engineers layer in foundation-model capabilities like retrieval and orchestration. Many teams need one lane heavily and the others in support. We help you weight the mix to the outcome you want, drawing from 200+ experts and 600+ delivered projects so the staffing matches the actual work.